Big Data is leading today’s industry and streaming that data in real time is very important and today’s need. Kafka is one of the stream line processor which can be used to stream big data in real time. So, now, let’s discuss what actually Kafka is and how it works.
Kafka is a distributed streaming platform having three capabilities:
- Publish and subscribe to streams of records, similar to a message queue.
- Store streams of records in a fault-tolerant durable way.
- Process streams of records as they occur.
Kafka is generally used for two broad classes of applications:
- Building real-time streaming data pipelines that reliably get data between systems or applications.
- Building real-time streaming applications that transform or react to the streams of data.
At a high-level Kafka gives the following guarantees:
- Messages sent by a producer to a particular topic partition will be appended in the order they are sent. That is, if a record M1 is sent by the same producer as a record M2, and M1 is sent first, then M1 will have a lower offset than M2 and appear earlier in the log.
- A consumer instance sees records in the order they are stored in the log.
- For a topic with replication factor N, we will tolerate up to N-1 server failures without losing any records committed to the log.
Kafka run as a cluster on one or more servers that can span multiple data centers. The Kafka cluster stores streams of records in categories called topics. Each record consists of a key, a value, and a timestamp.
APIs of Kafka:
Kafka has four core APIs on which Kafka is built and all the processes of Kafka are based on these four core APIs. All of these are described one-by-one.
- Producer API:
This API allows an application to publish a stream of records to one or more Kafka topics. This stream is then used by Consumer API (explained below) for processing. - Consumer API:
This API allows an application to subscribe to one or more topics and process the streams of records. - Streams API:
This allows and application to act as stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams. - Connector API:
This allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table.
In Kafka, the communication between the clients and the servers is done with simple, high performance, language agnostic TCP Protocol. This protocol is versioned and maintains backwards compatibility with older version. We provide a Java client for Kafka, but clients are available in many language.

Topics and Logs:
A topic is a category or feed name to which records are published. Topics in Kafka are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it.
For each topic, the Kafka cluster maintains a partitioned log that looks like this:
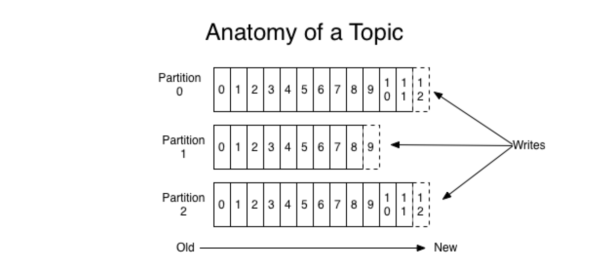
Each partition is an ordered, immutable sequence of records that is continually appended to—a structured commit log. The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
The partitions in the log serve several purposes. First, they allow the log to scale beyond a size that will fit on a single server. Each individual partition must fit on the servers that host it, but a topic may have many partitions so it can handle an arbitrary amount of data. Second they act as the unit of parallelism—more on that in a bit.
Distribution:
The partitions of the log are distributed over the servers in the Kafka cluster with each server handling data and requests for a share of the partitions. Each partition is replicated across a configurable number of servers for fault tolerance.
Each partition has one server which acts as the “leader” and zero or more servers which act as “followers”. The leader handles all read and write requests for the partition while the followers passively replicate the leader. If the leader fails, one of the followers will automatically become the new leader. Each server acts as a leader for some of its partitions and a follower for others so load is well balanced within the cluster.
Producer:
Producers publish data to the topics of their choice. The producer is responsible for choosing which record to assign to which partition within the topic. This can be done in a round-robin fashion simply to balance load or it can be done according to some semantic partition function (say based on some key in the record). More on the use of partitioning in a second!
Consumer:
Consumers label themselves with a consumer group name, and each record published to a topic is delivered to one consumer instance within each subscribing consumer group. Consumer instances can be in separate processes or on separate machines. If all the consumer instances have the same consumer group, then the records will effectively be load balanced over the consumer instances. If all the consumer instances have different consumer groups, then each record will be broadcast to all the consumer processes.
Kafka only provides a total order over records within a partition, not between different partitions in a topic. Per-partition ordering combined with the ability to partition data by key is sufficient for most applications. However, if you require a total order over records this can be achieved with a topic that has only one partition, though this will mean only one consumer process per consumer group.
This above all information are the basics of Kafka. These basics are important to understand before installing, configuring and using Kafka. Stay Tuned, for Installation and configuration!
I hope this will be helpful for a lot of people who still have confusion! Please comment, if you know something else which I missed or stated incorrectly.

One thought on “What is Kafka and how it works?”